
In software development, we joke about the three hardest things being naming things, cache invalidation, and off-by-one errors. But for the first one, it’s no joke. We’ve been naming things wrong.
Naming conventions are steeped in racism and patriarchy. Master, slave, blacklist, whitelist — these aren’t just words. They’re relics of a mindset we need to leave behind. Toss artificial intelligence into the mix, and it’s the punchline we didn’t see coming.
Choosing inclusive naming conventions
Naming is everything in software development. It’s how we make sense of our code and how we make things work. But it’s not enough to name for readability, avoiding collisions, debugging, and sharing intent.
We have a choice to use naming conventions that reinforce a discriminatory mindset. Master/slave and blacklist/whitelist are a few examples influenced by racism and patriarchy. If you dig deeper into common technology terms, you’ll find even more that stem from sexism and ableism.
We have a choice to use inclusive language like main, primary, replica, denylist, and allowlist. In 2019, Ruby on Rails replaced whitelist with allowlist and blacklist with denylist. In 2021, Gitlab updated their default branch name from master to main.
At Clockwork, we made the choice to use inclusive naming conventions.
How we made the change
It started with a Slack post that prompted candid discussion.
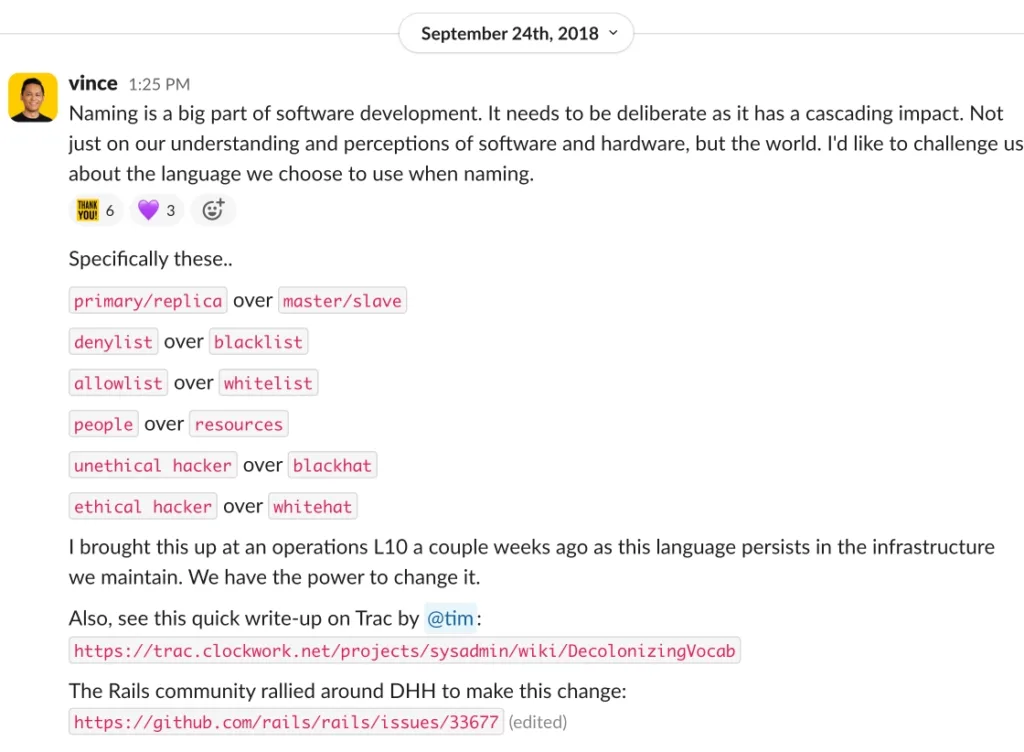
The discussions eventually led to a project where our operations engineers would find and replace non-inclusive naming conventions in our infrastructure. We started by replacing master/slave in our Icinga monitoring system with primary/replica.
As we made the changes to our infrastructure, the team took the next step on their own to update the documentation for our outbound email server from blacklist/whitelist to denylist/allowlist. Then they started to break the habit of using spurned words and phrases, both verbally and in written communication. Changing verbal habits was a bit harder, but within weeks, we were correcting ourselves immediately after using spurned words.
Navigating the challenges
A challenging part of the project was determining the scope. What do you do when you’re unable to make those changes because you’re subject to a platform provider?
A guideline we set for ourselves was to update our documentation with our preferred language. We will continue using inherited language when technically required (e.g. documenting specific commands or labels used in upstream tooling). We did this all with the expectation that we will give feedback to the companies that maintain those tools. We will share our changes and encourage them to consider similar changes.
It may feel like a small thing, but if everyone who felt this way submitted similar feedback, we’d likely see some changes.
A challenge we did not experience was resistance from our team. Our engineers welcomed the naming changes. This openness can be attributed to hiring humans who value diversity, inclusion, equity, and belonging, and an organization that cultivates an inclusive and people-centered culture.
This might not be the case for every organization.
In an industry in which there has been poor racial and gender representation, it has been eye-opening to see the reactions to this movement. There is resistance and a lot of color blindness among us. People defend the original intent of these terms rather than considering their impact. It’s not hard to see that associating positive things with “white” and negative things with “black” is, at worst, deeply offensive and at best entirely unnecessary.
So let’s change it with inclusive naming conventions.
Biases and AI
As generative artificial intelligence weaves itself into the fabric of our daily lives, the urgency for inclusive naming has skyrocketed from something we should do to something we must do. Here’s why.
Large language models (LLMs) are trained on data from human-generated text, which contain biases. And these biases can be amplified through LLMs. We have a responsibility to ensure that the AI solutions we create and interact with reflect the diversity and inclusivity of the world it serves. Failure to do so will not only reflect those biases but also exacerbate them. Because when LLM responses default to names, terms, or language that exclude or marginalize, they perpetuate a discriminatory mindset.
Organizations that use AI must minimize bias by governing how it is used safely, securely, and responsibly. It should be table stakes to have a code of ethics, acceptable use policy, and data security and privacy standards that address the proper and improper uses of AI.
For example, at Clockwork, we’ve introduced an AI Community of Practice group whose purpose is to expand our use of innovative AI technologies while also providing guidance and best practices around mitigating the effects of bias in results.
And for organizations that create AI, it’s critical to curate datasets that are diverse and representative of the global population. This involves not only including text from a wide range of cultures, languages, and perspectives but also actively seeking out and incorporating content that reflects underrepresented voices. By doing so, AI can learn from a richer tapestry of human experience, leading to more balanced and inclusive responses.
In either case, organizations that have diverse perspectives will produce better solutions and services that mirror the world they serve.
Originally published in 2018, this article was later updated to expand on biases and AI.


